


Industry News
Facebook is enabling machines to "see and speak" by bridging machine vision and natural language processing
Date:2017-12-22
Source:Samsun Technology
“视觉对话”(Visual Dialogue)是个最近新兴的研究方向。它集机器视觉、自然语言处理、以及对话系统这三个十分热门的研究方向为一体,主要目标就是教会机器如何用自然语言与人类交流视觉数据。
现有的对话系统能力范围极广:在这个范围的一头是为特定目标设计的任务驱动的聊天机器人,比如可以帮你订飞机票聊天机器人,而在另一头则是可以和你侃大山的“闲聊机器人”。在这个范围里,视觉对话处于这两个极端中间:它是自由的对话,但是对话的内容却会受到一个具体的图像的限制。


对视觉内容进行明确的推理
语言与视觉数据最重要的关联之一就是用自然语言提问,比如:“图片中的动物是什么?”,或者“沙滩上坐着多少人?”虽然每个问题都要求解决不同的问题,但是目前绝大多数最先进的系统都会使用整体方法,比如同样的计算图或者网络来计算出答案。但是,这种模型的解释性有限,并且对更复杂的推理任务,比如下图中所展示的“有多少物体的体积与那个球一样?”来说效率不高。
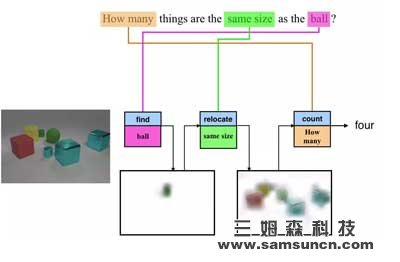
在上图中的例子里,一个模块会“寻找”图中的球,另外一个模块则会“寻找”同样体积的物体,而最后一个模块则会数“有多少”这样的物体。最重要的是,这些模块可以重复的用于不同的图片和问题,比如“找球”模块也可以用来回答“图中的球比立方体多吗?”这个问题。从图中,我们还可以看到中间以“注意图”(Attention Map)的方式告诉我们模型正在看哪个部位的那些步骤是一种可被理解的输出。
虽然原先的成功所依赖的是一个不可微的自然语言处理器,2017 年的 ICCV(国际计算机视觉大会)上有两篇论文展示了如何从端到端的训练这种系统。这两篇论文的作者发现,这种方式对于回答 CLEVR 数据集中的困难成分问题来说至关重要。(CLEVR 数据集是在 CVPR 2016 所公布的一款用于测试成分语言和基本视觉推理的数据集,后由 Facebook 人工智能研究室(FAIR)和斯坦福大学联手公开)。
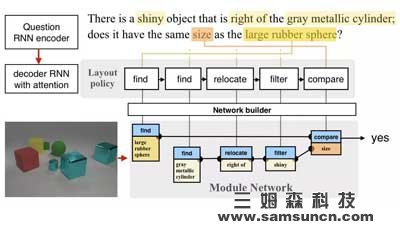 图 |在《Learning to Reason: End-to-End Module Networks for Visual Question Answering》一文中,作者们首先在问题上做出了一个含有编码器和解码器的递归神经网络(RNN)的政策/程序。这个程序再搭建了一个模块网络,并在图片上运行这个网络来回答问题。
图 |在《Learning to Reason: End-to-End Module Networks for Visual Question Answering》一文中,作者们首先在问题上做出了一个含有编码器和解码器的递归神经网络(RNN)的政策/程序。这个程序再搭建了一个模块网络,并在图片上运行这个网络来回答问题。
不过,这两篇论文提出了两种不同的构架。在第一篇,由 Facebook 人工智能研究院和斯坦福大学联手发表的论文(Inferring and Executing Programs for Visual Reasoning)中,研究人员们在不同的模块中使用了不同的参数,但又使用了同样的网络结构。在第二篇,由 Facebook 人工智能研究院和加州大学伯克利分校,以及波士顿大学联手发表的论文(Learning to Reason: End-to-End Module Networks for Visual Question Answering)中,作者们在不同的模块中采取了不同的计算方式,但是又通过嵌入问题所用的语言分享了参数。
虽然这两款模型的构架不一样,但是它们却得出了一个同样的结论:我们在监督程序预测时需要使用正确参考标准(Ground Truth)程序来确保结果,不过我们仅需少量的训练数据。此外,第一篇论文(Inferring and Executing Programs )还显示,使用加强学习来让网络学会最优的端到端还比正确参考标准程序提高了很多,并且可以针对新问题和答案进行精准的调整。
而最近又出现了两款网络构架:RelationNet 和 FiLM。在训练时不使用任何正确参考标准程序的情况下,使用这两个构架的整体网络不但保持了性能,甚至还实现了提高。当然,这也意味着它们失去了原有的明确和可理解的推理结构。
此外,第一篇论文(Inferring and Executing Programs)使用的从人群中收集到的问题,而不是 CLEVR 数据集里那些生成的问题。在这方面,没有任何模型表现出了良好的普遍性。相似的是,在使用视觉问答(Visual Question Answering,VQA)数据集中的真实图片和问题进行测试时,第二篇论文(Learning to Reason)只实现了有限的性能提高,很有可能因为 VQA 数据集中的问题不需要像 CLEVR 数据集里的那么困难的推理。总体来说,我们很高兴可以在未来探索新的主意,搭建真正具有成分性和解释性的模型,来对应现实世界中新的设置和程序所创造的挑战。
拟人的视觉对话
Dhruv Batra,Devi Parikh,以及他们在佐治亚理工学院和卡耐基梅隆大学的学生们针对嵌入在图片中的自然语言对话进行了研究,并且开发出来一款全新的 2 人对话数据收集协议,来生成一个大规模的视觉对话数据集(VisDial)。这个数据集中针对 12 万张图片的每段对话都有 10 对问答,共有 120 万对对话问答。
为了解决这一问题,佐治亚理工学院,卡耐基梅隆大学,以及 Facebook 人工智能研究院的研究人员们推出了全世界首个由目标驱动(深度加强学习),来帮助训练视觉问答以及视觉对话代理的论文:“Learning Cooperative Visual Dialog Agents with Deep Reinforcement Learning”。
他们开发出一款合作“图片猜测”游戏 GuessWhich,要求一个“提问者”Q-BOT 和一个“回答者”A-BOT 用自然语言进行对话。在游戏开始之前,A-BOT 会被提供一张 Q-BOT 不知道的图片,而 A-BOT 和 Q-BOT 都会被提供同样的对图片的自然语言描述。在接下来的每轮中,Q-BOT 都会生成一个问题,A-BOT 对这个问题作出回答,然后两者更新它们的状态。在 10 轮之后,Q-BOT 必须猜测这张图片,即在多张图片中选出这张图片。
我们发现,这些加强学习训练出来的机器人的性能远超传统监督学习产生的机器人。最有意思的是,虽然监督学习的 Q-BOT 会尝试模仿人类问问题,加强学习的 Q-BOT 却会改变策略,提出 A-BOT 更擅长回答的问题,最终产生得到最多信息,最有益于团队的对话。
由目标驱动的训练的一个替代品就是使用可以区分人类和代替生成回答的对抗性损失或者知觉丧失。这个主意已经由 Facebook 人工智能研究院以及佐治亚理工学院的研究人员在研究了,并且会在 NIPS 2017(神经信息处理系统大会)公布他们的成果:“Best of Both Worlds: Transferring Knowledge from Discriminative Learning to a Generative Visual Dialog Mode”。
此外,这篇由德国的马普信息学研究所,加州大学伯克利分校,以及 Facebook 人工智能研究院的研究人员所发表的论文:“Speaking the Same Language: Matching Machine to Human Captions by Adversarial Training”也是针对这个话题的。这篇论文表示,在同一时间为一张图片生成多个描述,要比一次生成一个更能让模型学会如何生成更多样化,更拟人的图片描述。
我们需要开放的跨领域合作
作为人类,我们大脑功能种很重要的一部分都是通过视觉处理,而自然语言则是我们交流的方式。创造可以将视觉和语言连接在一起的人工智能代理是一个即兴奋也困难的任务。我们在此文中讨论了两个研究方向:明确的视觉推理和拟人的视觉对话。虽然我们在进步,但是我们面前还有许多挑战。为了保证向前的脚步不停,坚持在 Facebook 人工智能研究院,学术界,以及整个人工智能生态圈之间机型长期开放的基础性跨领域研究合作是至关重要的。
现有的对话系统能力范围极广:在这个范围的一头是为特定目标设计的任务驱动的聊天机器人,比如可以帮你订飞机票聊天机器人,而在另一头则是可以和你侃大山的“闲聊机器人”。在这个范围里,视觉对话处于这两个极端中间:它是自由的对话,但是对话的内容却会受到一个具体的图像的限制。
图 | 未来可能的应用 1:一个智能代理通过视觉能力和自然语言推理来帮助(组织)一个人停在消防栓前面
虽然视觉对话的研究还处于初期,但是这项技术已经有着众多的应用场景了。比如通过一系列问答来帮助弱视或盲人理解网上的图片以及拍摄周围的照片,或者帮助医疗人员更好的理解医疗成像。它也可以用于虚拟现实(VR)或增强现实(AR)程序里,帮助用户与虚拟伙伴用语言针对所见到的画面进行交流。
图:未来可能的应用 2:一个虚拟伙伴通过看到与用户相同的图片来进行交流
在达到这一点之前,我们需要攻克许多基础性的难关。最近,Facebook 针对两点进行了研究:一个是对视觉内容进行明确的推理,一个是拟人的视觉对话。对视觉内容进行明确的推理
语言与视觉数据最重要的关联之一就是用自然语言提问,比如:“图片中的动物是什么?”,或者“沙滩上坐着多少人?”虽然每个问题都要求解决不同的问题,但是目前绝大多数最先进的系统都会使用整体方法,比如同样的计算图或者网络来计算出答案。但是,这种模型的解释性有限,并且对更复杂的推理任务,比如下图中所展示的“有多少物体的体积与那个球一样?”来说效率不高。
图 | 将问题模块化可以实现可解释以及成分推理
为了解决这一问题,加州大学伯克利分校的研究人员在 2016 年的 CVPR(IEEE 国际计算机视觉与模式识别会议)上提出了一种“神经模块网络(Neural Module Networks)”,可以将计算分解成明确的模块。在上图中的例子里,一个模块会“寻找”图中的球,另外一个模块则会“寻找”同样体积的物体,而最后一个模块则会数“有多少”这样的物体。最重要的是,这些模块可以重复的用于不同的图片和问题,比如“找球”模块也可以用来回答“图中的球比立方体多吗?”这个问题。从图中,我们还可以看到中间以“注意图”(Attention Map)的方式告诉我们模型正在看哪个部位的那些步骤是一种可被理解的输出。
虽然原先的成功所依赖的是一个不可微的自然语言处理器,2017 年的 ICCV(国际计算机视觉大会)上有两篇论文展示了如何从端到端的训练这种系统。这两篇论文的作者发现,这种方式对于回答 CLEVR 数据集中的困难成分问题来说至关重要。(CLEVR 数据集是在 CVPR 2016 所公布的一款用于测试成分语言和基本视觉推理的数据集,后由 Facebook 人工智能研究室(FAIR)和斯坦福大学联手公开)。
不过,这两篇论文提出了两种不同的构架。在第一篇,由 Facebook 人工智能研究院和斯坦福大学联手发表的论文(Inferring and Executing Programs for Visual Reasoning)中,研究人员们在不同的模块中使用了不同的参数,但又使用了同样的网络结构。在第二篇,由 Facebook 人工智能研究院和加州大学伯克利分校,以及波士顿大学联手发表的论文(Learning to Reason: End-to-End Module Networks for Visual Question Answering)中,作者们在不同的模块中采取了不同的计算方式,但是又通过嵌入问题所用的语言分享了参数。
虽然这两款模型的构架不一样,但是它们却得出了一个同样的结论:我们在监督程序预测时需要使用正确参考标准(Ground Truth)程序来确保结果,不过我们仅需少量的训练数据。此外,第一篇论文(Inferring and Executing Programs )还显示,使用加强学习来让网络学会最优的端到端还比正确参考标准程序提高了很多,并且可以针对新问题和答案进行精准的调整。
而最近又出现了两款网络构架:RelationNet 和 FiLM。在训练时不使用任何正确参考标准程序的情况下,使用这两个构架的整体网络不但保持了性能,甚至还实现了提高。当然,这也意味着它们失去了原有的明确和可理解的推理结构。
此外,第一篇论文(Inferring and Executing Programs)使用的从人群中收集到的问题,而不是 CLEVR 数据集里那些生成的问题。在这方面,没有任何模型表现出了良好的普遍性。相似的是,在使用视觉问答(Visual Question Answering,VQA)数据集中的真实图片和问题进行测试时,第二篇论文(Learning to Reason)只实现了有限的性能提高,很有可能因为 VQA 数据集中的问题不需要像 CLEVR 数据集里的那么困难的推理。总体来说,我们很高兴可以在未来探索新的主意,搭建真正具有成分性和解释性的模型,来对应现实世界中新的设置和程序所创造的挑战。
拟人的视觉对话
Dhruv Batra,Devi Parikh,以及他们在佐治亚理工学院和卡耐基梅隆大学的学生们针对嵌入在图片中的自然语言对话进行了研究,并且开发出来一款全新的 2 人对话数据收集协议,来生成一个大规模的视觉对话数据集(VisDial)。这个数据集中针对 12 万张图片的每段对话都有 10 对问答,共有 120 万对对话问答。
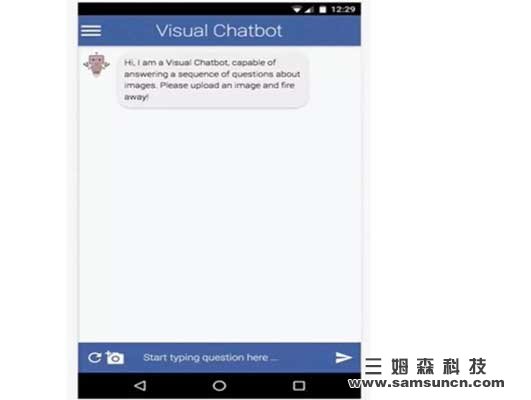
图 | 视觉对话代理的演示。用户会上传一张图片,代理则会以提出一个标题,“一个在中间有着钟楼的大型建筑”来开始对话,再回答用户所提的一系列问题。
由于视觉对话处于多个研究方向的交叉点上,它也促进了不同领域之间的合作来解决共有的问题。为了帮助这整个领域,Batra 和 Parikh 他们向对话研究者公开了这个视觉对话的数据集以及相关的源代码,让他们可以针对自己的问题开发自己的数据集。
对话研究一个可能会让人感觉到反直觉的特性就是会把对话视为一个静态监督学习问题,而非一个互动代理学习问题。在实质上,在监督学习中的每轮(t),对话模型都会被人工的“注入”两个人类之间的对话,并被要求回答一个问题。但是机器的回答却会被直接丢掉,因为在下一轮(t+1),机器会被提供正确参考标准,即含有人类的回答而不是机器的回答的对话。因此,机器永远不可能引导对话,因为这样会导致对话脱离数据集,让它变得无法被评估。由于视觉对话处于多个研究方向的交叉点上,它也促进了不同领域之间的合作来解决共有的问题。为了帮助这整个领域,Batra 和 Parikh 他们向对话研究者公开了这个视觉对话的数据集以及相关的源代码,让他们可以针对自己的问题开发自己的数据集。
为了解决这一问题,佐治亚理工学院,卡耐基梅隆大学,以及 Facebook 人工智能研究院的研究人员们推出了全世界首个由目标驱动(深度加强学习),来帮助训练视觉问答以及视觉对话代理的论文:“Learning Cooperative Visual Dialog Agents with Deep Reinforcement Learning”。
他们开发出一款合作“图片猜测”游戏 GuessWhich,要求一个“提问者”Q-BOT 和一个“回答者”A-BOT 用自然语言进行对话。在游戏开始之前,A-BOT 会被提供一张 Q-BOT 不知道的图片,而 A-BOT 和 Q-BOT 都会被提供同样的对图片的自然语言描述。在接下来的每轮中,Q-BOT 都会生成一个问题,A-BOT 对这个问题作出回答,然后两者更新它们的状态。在 10 轮之后,Q-BOT 必须猜测这张图片,即在多张图片中选出这张图片。
我们发现,这些加强学习训练出来的机器人的性能远超传统监督学习产生的机器人。最有意思的是,虽然监督学习的 Q-BOT 会尝试模仿人类问问题,加强学习的 Q-BOT 却会改变策略,提出 A-BOT 更擅长回答的问题,最终产生得到最多信息,最有益于团队的对话。
由目标驱动的训练的一个替代品就是使用可以区分人类和代替生成回答的对抗性损失或者知觉丧失。这个主意已经由 Facebook 人工智能研究院以及佐治亚理工学院的研究人员在研究了,并且会在 NIPS 2017(神经信息处理系统大会)公布他们的成果:“Best of Both Worlds: Transferring Knowledge from Discriminative Learning to a Generative Visual Dialog Mode”。
此外,这篇由德国的马普信息学研究所,加州大学伯克利分校,以及 Facebook 人工智能研究院的研究人员所发表的论文:“Speaking the Same Language: Matching Machine to Human Captions by Adversarial Training”也是针对这个话题的。这篇论文表示,在同一时间为一张图片生成多个描述,要比一次生成一个更能让模型学会如何生成更多样化,更拟人的图片描述。
我们需要开放的跨领域合作
作为人类,我们大脑功能种很重要的一部分都是通过视觉处理,而自然语言则是我们交流的方式。创造可以将视觉和语言连接在一起的人工智能代理是一个即兴奋也困难的任务。我们在此文中讨论了两个研究方向:明确的视觉推理和拟人的视觉对话。虽然我们在进步,但是我们面前还有许多挑战。为了保证向前的脚步不停,坚持在 Facebook 人工智能研究院,学术界,以及整个人工智能生态圈之间机型长期开放的基础性跨领域研究合作是至关重要的。
